Evaluating AI for Thematic Analysis
When I started developing QualBot, one of the earliest challenges I faced was how to evaluate it. In quantitative research, you can look at p-values, margins of error, and model fit. But how do you judge whether one thematic analysis is better than another? Every researcher brings a unique lens—different priorities, interpretive styles, and theoretical frameworks. That subjectivity is part of what makes qualitative research so powerful, but it also makes evaluation… tricky.
This post is my attempt at summarizing how I approached the problem of evaluating AI for thematic analysis. It outlines the process I followed to create an evaluation framework for QualBot—one that balances rigor with the nuance qualitative work demands. From defining a gold standard analysis to benchmarking AI-generated outputs, the goal was simple: hold AI to the same standards we expect from human analysts.

The Challenge: Evaluating AI-generated Thematic Analysis
Qualitative analysis relies heavily on researchers' nuanced understanding of themes, context, and the complexities hidden in interview transcripts and open-ended responses. Traditional large language models have limitations when it comes to contextual depth, hallucinations, and lack of structured report generation. Simply throwing data at an AI doesn't guarantee a coherent, replicable analysis.
That's where a well-defined evaluation strategy comes in. We need something that holds these tools accountable to the same standards we use for robust human-driven qualitative work. That includes comparing them against a "gold standard" thematic analysis, evaluating the accuracy of identified themes, and making sure the quotes AI picks are relevant and genuinely found in the data.
Developing a Gold Standard
To understand how well QualBot performs compared to traditional qualitative analysis, we needed a solid point of reference—something we could treat as a "gold standard." For that, we turned to a publicly available dataset from the Harvard Dataverse, which included rich, open-ended responses suitable for a full thematic analysis.
We conducted a manual thematic analysis of this dataset using the widely respected Braun & Clarke (2003) framework. This approach provides a structured yet flexible method for identifying and analyzing patterns of meaning across qualitative data. Our process followed four main stages:
- Segment transcripts and code: We read each transcript line by line, highlighting meaningful passages and assigning preliminary codes to segments of text that conveyed distinct ideas, concerns, or experiences.
- Group codes into themes: We then reviewed the full set of codes and began clustering them into broader themes and subthemes based on shared meanings. This step involved identifying patterns across participants and consolidating individual codes into higher-level insights.
- Review and refine themes: To ensure conceptual clarity, we created a thematic map to visualize how the themes related to one another. We refined theme labels, adjusted boundaries where needed, and ensured the analysis maintained internal coherence and relevance to the research context.
- Write the final report: We compiled our findings into a structured report that presented each theme, supported by verbatim quotes from the transcripts. This report included detailed thematic descriptions, conclusions, and practical recommendations based on the data.
This analysis has been published to an Open Science Framework (OSF) repository to encourage transparency, replication, and community validation. Our goal is to support an open science approach to qualitative AI evaluation—where gold standards are not held behind closed doors but are instead shared, critiqued, and improved collaboratively. This kind of openness is essential if we want to develop fair and credible benchmarks for assessing the value of AI tools in qualitative research.
Benchmarking vs. State-of-the-Art LLMs
To evaluate QualBot's performance in a meaningful context, we selected GPT-o1 and Gemini 2.0 Pro as benchmark models. At the time of evaluation, these were considered among the most capable general-purpose language models available, particularly for tasks requiring advanced reasoning, text generation, and contextual understanding.
Our aim was not only to assess QualBot in isolation, but to understand how it compared to the current state of the art in large language models. GPT-4-turbo and Gemini 2.0 were chosen specifically because of their reputations for high performance across a wide range of natural language processing benchmarks, making them suitable reference points for comparison in the domain of qualitative analysis.
Defining Evaluation Metrics
We focused on theme retrieval and quote retrieval as core evaluation metrics because they capture the two most critical outputs of any thematic analysis: the identification of key patterns in the data and the evidence used to support them. Themes reflect the analytical interpretation of the dataset, while quotes provide the empirical grounding for those interpretations. Evaluating both ensures that the AI is not only extracting meaningful insights but also doing so in a way that is traceable, transparent, and consistent with qualitative research standards.
Theme retrieval metrics
- Precision: The proportion of themes generated by QualBot that were correct—i.e., themes that matched those identified in the gold standard. High precision means fewer irrelevant or spurious themes were introduced by the AI.
- Recall: The proportion of gold standard themes that QualBot successfully captured. High recall indicates that the AI was comprehensive in its coverage of the key ideas in the data.
- F1 Score: The harmonic mean of precision and recall, providing a balanced view that rewards models which perform well on both dimensions. This is a useful metric when there's a trade-off between generating too few or too many themes.
- Similarity Score: While the metrics above rely on exact or near-exact matches, we also included a subjective similarity assessment using a large language model (LLM). In this step, we asked an LLM to judge how closely QualBot's themes matched the meaning and intent of the gold standard themes—even if the wording or structure differed.
Quote retrieval metrics
In addition to evaluating themes, we assessed the quality and accuracy of the quotes generated by AI, since verbatim evidence is central to rigorous qualitative analysis. We focused on three key dimensions:
- Hallucination Rate: We verified whether the quotes included in the AI output were actually present in the original transcripts. Any fabricated or altered text was flagged as a hallucination. A low hallucination rate indicates that the model accurately references source material rather than inventing content.
- Relevance: We assessed whether the quotes were meaningfully connected to the themes they were intended to support. A quote was considered relevant if it provided clear, contextual evidence for the thematic label under which it was placed. This ensures the integrity of theme development and prevents superficial or mismatched examples.
- Coverage: We checked whether each identified theme was supported by at least one relevant quote. Full coverage indicates that the model not only identifies themes but also grounds them in participant data, which is essential for transparency and trustworthiness in qualitative reporting.
Evaluation Results
Theme retrieval
With the gold standard analysis complete, we now had a clear sense of the "ground truth"—the set of themes and subthemes that a trained human researcher would extract from the data. This gave us a firm foundation for assessing QualBot's performance not just qualitatively, but quantitatively.
We then applied evaluation metrics to move beyond anecdotal judgments and systematically measure how well QualBot's themes aligned with those in the gold standard.
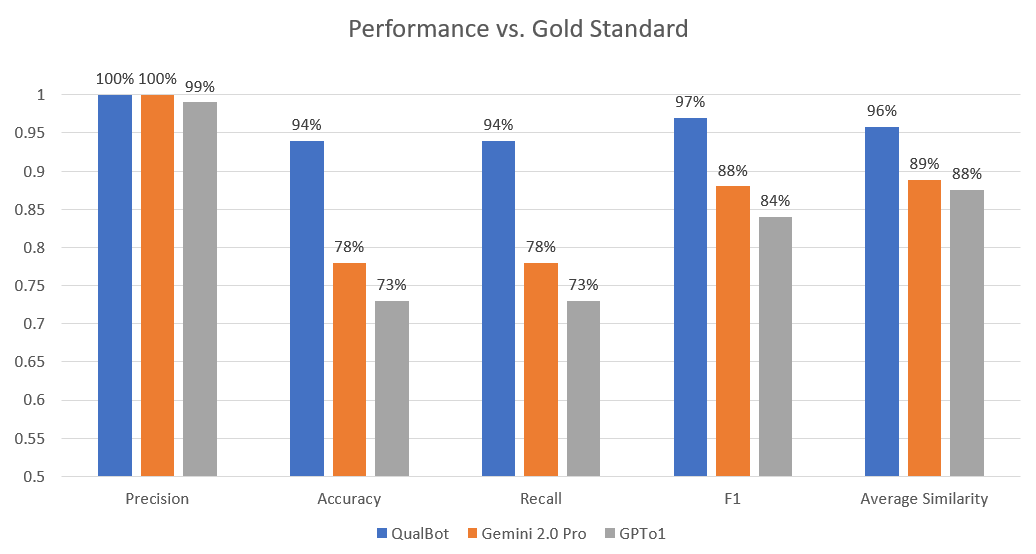
The evaluation results showed that all three models had great precision. They all retrieved themes that were in fact present in the gold standard. However, QualBot outperformed both Gemini 2.0 Pro and GPT-o1 across all other metrics.
- Precision: QualBot achieved 100% precision, indicating that all of its identified themes matched those in the gold standard.
- Accuracy and Recall: QualBot scored 94% on both metrics, compared to 78% and 73% for Gemini and GPT-01 respectively, demonstrating more effective identification of key themes.
- F1 Score: QualBot led with 97%, significantly higher than Gemini (88%) and GPT-01 (84%), showing strong balance between precision and recall.
- Semantic Similarity: QualBot achieved 96% similarity with gold standard themes, compared to 89% for Gemini and 88% for GPT-01.
Quote retrieval
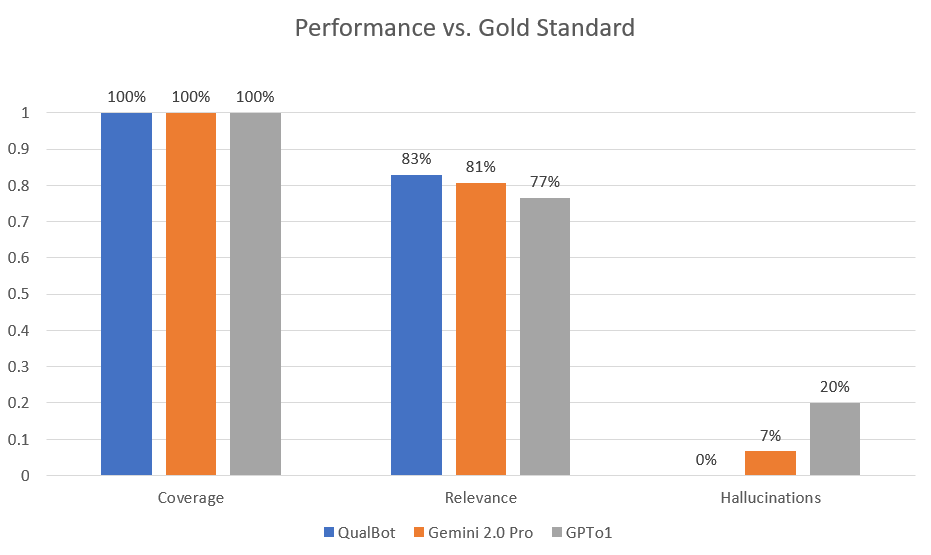
The quote-level evaluation results comparing the three models showed:
- Coverage: All three models achieved 100% coverage, with every identified theme supported by at least one quote.
- Relevance: QualBot led with 83% quote relevance, followed by Gemini at 81% and GPT-01 at 77%, showing better alignment between quotes and themes.
- Hallucination Rate: QualBot produced zero hallucinated quotes (0%), while Gemini had a 7% rate and GPT-01 a significantly higher 20% rate, demonstrating superior data integrity.
These results support QualBot's use in applications where traceability to source data and evidentiary accuracy are essential.
Why QualBot Stands Out
QualBot's performance is the result of an "evals-first" development approach. Rather than building a system and evaluating it afterward, we defined clear performance metrics from the outset—including precision, recall, F1 score, thematic relevance, hallucination rate, and quote coverage. These benchmarks guided every iteration of development.
We then optimized relentlessly against those metrics, refining model prompts, logic chains, and output structure to improve performance. Crucially, to avoid overfitting and preserve generalizability, the test corpus used for evaluation was kept completely separate from any training or tuning data. This ensured that gains in performance reflected true improvements in reasoning and structure, not memorization or corpus-specific tailoring.
By grounding development in transparent, measurable outcomes and maintaining a strict separation between tuning and evaluation datasets, QualBot was able to outperform general-purpose LLMs in both thematic accuracy and quote reliability. The result is a system purpose-built for qualitative research, capable of producing structured, evidence-based outputs that stand up to scrutiny.
Conclusion
The future of AI for qualitative research is bright, but only if we hold these tools to the same rigorous standards we apply to human-led analysis. By comparing AI outputs against a gold standard, reviewing theme quality, and ensuring quotes are real and relevant, we can gain confidence in AI's value-add. QualBot's performance in these evaluations demonstrates its credibility as a powerful assistant to researchers, offering the speed and consistency of AI without sacrificing the depth that makes qualitative work so meaningful.
References
- Braun, V., & Clarke, V. (2003). Using thematic analysis in psychology. Qualitative Research in Psychology, 3(2), 77–101.
- West, S., Beilin, R., & Wagenaar, H. (2019). Dataset: Introducing a practice perspective on monitoring for adaptive management. Harvard Dataverse