Introducing QualBot Coding
Fast, accurate, and scalable coding for open-ended survey responses

The Lost Ark
Tell me if this ever happened to you: You're handed a once-in-a-career treasure trove. 60,000 open-ended responses to a soul-searching question like "What matters most to you?" or "What's your biggest hope or fear?" Then, in the fine print… The data are from 2006. 🤯
Nineteen years of silence. The file just sat there, quietly gathering digital dust, too overwhelming for any human analyst to touch.
You still feel like Indiana Jones stumbling into an ancient treasure. So you do what any desperate researcher would in 2025: Hurl OpenAI API credits at it!
And yes—it works. Sort of. After weeks of prompt tweaks, model wrangling, cost calculations, and way too many coffee-fueled debugging sessions… you get the insights. They're brilliant. Just 19 years late!
Experiences like that have haunted me for years—and they're what pushed me to build our new QualBot Coding feature: Something better than a spreadsheet, smarter than a vanilla LLM, and faster than… well, 19 years.
What Does It Take to Get Coding Right?
Turning free-text into structured insight isn't a mechanical task—it's a craft. To do it right, you need clear categories, precise instructions, guidance on edge cases, and careful checks for consistency. You need interrater reliability, training, supervision, and time. In other words: people, process, and patience.
The problem? Most real-world projects don't have enough of any of those. Coders get fatigued. Budgets get slashed. Timelines shift. And before long, your "Other (please explain)" becomes just another column nobody touches.
Can AI Do Better?
I'm not one for oversimplification, but in this particular case, the only fair answer is...
...it sure can!
Mellon et al. (2024) set out to answer the question, "Can AI accurately code open-text survey responses?" They tested a lineup of large language models (LLMs), old-school supervised classifiers, and—most importantly—a second trained human coder, all asked to categorize responses to one of the most iconic questions in political science: "What is the most important issue facing the country?"
The result? One of the top-performing LLMs scored 93.9% accuracy, virtually matching human performance (94.7%), and even outperforming a neural net trained on 1,000 real-world examples. In the tougher "new data" scenario—where models had to label completely unseen answers—Claude-1.3 still held its own, trailing a trained human coder by just a few points and handily beating supervised models trained on over half a million examples.
That's impressive. And remember: these were 2023-era LLMs. That's a decade ago in AI time.
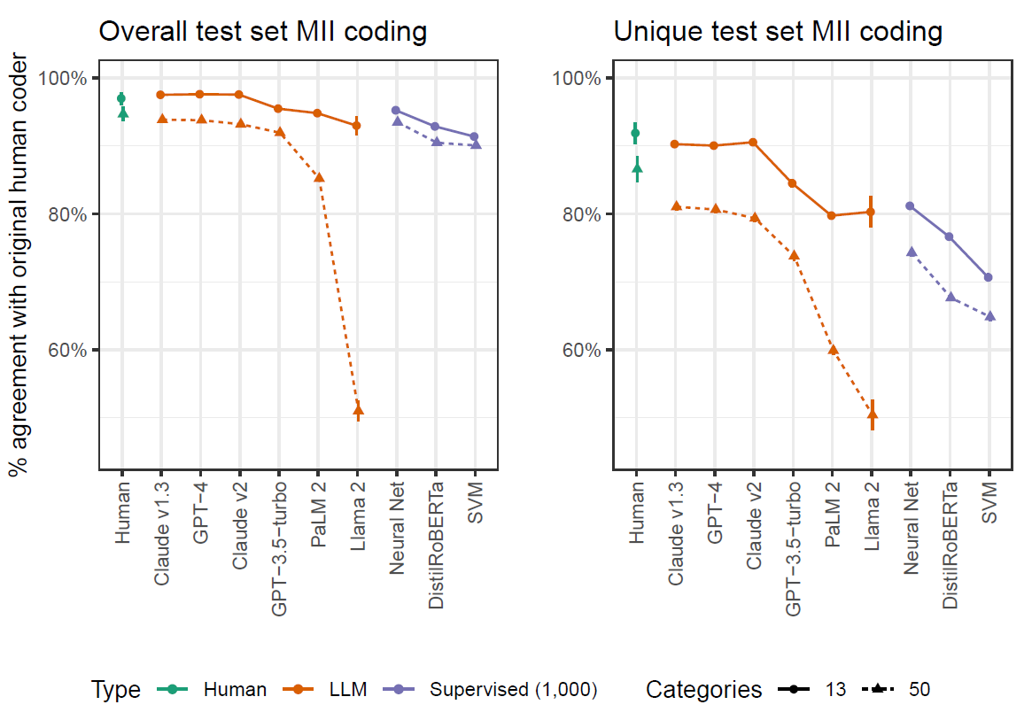
Figure 1: Percentage of responses that agree with original human coder across overall and unique test sets. Supervised models trained on 1,000 cases from BESIP waves 21-23 (Reproduced from Mellon et al., 2024).
But here's the kicker: reproducing these results today would still require more keystrokes than a Chopin concerto. The prompts, cleaning steps, retries, error handling, and manual edits were anything but plug-and-play. So yes, AI can definitely code open-ends—but not without serious scaffolding. And that's exactly why we built QualBot Coding.
Enter QualBot Coding 🦾
QualBot was built to solve a real problem: researchers drowning in open-text responses without the time or budget to code them properly.
It's built specifically for researchers who don't want to spend weeks hand-labeling open-ended responses—or babysitting a fragile AI pipeline. With QualBot, you can upload your data, define your categories, add optional metadata or instructions, and click "Go." Minutes later, you've got a structured dataset with codes, confidence scores, and verbatim quotes. All wrapped in a clean, human-auditable format.
The goal? Super-human performance—fast, transparent, and scalable coding, with accuracy surpassing human coders.
As with every feature we build into QualBot, we take an "evals-first" approach: define the benchmark first, then optimize relentlessly until we pass it. For open-end coding, we chose the British Election Study (BES) Internet Panel as our benchmark—specifically, responses to the "Most Important Issue" question, a staple in political science research.
This dataset is ideal for evaluation: it has been professionally hand-coded by humans into both 13 broad and 50 fine-grained categories, making it perfect for benchmarking model precision. We treated those human-coded labels as the gold standard and followed the protocol from Mellon et al. (2024) to compare QualBot's predictions against those of a second trained human coder.
We wanted to give our new QualBot Coding feature the toughest possible challenge to ensure it would pass muster. So we tested it on a random sample of 10,000 open-text responses from the BES dataset, using the more demanding 50-category codebook. The results? QualBot Coding crushed it—97.2% accuracy, in under 10 minutes, for just one dollar.
| Metric | Human | QualBot |
|---|---|---|
| Accuracy vs. gold standard | 94.7% | 97.2% |
| Cohen's κ | 0.947 | 0.964 |
| Minutes / 10,000 rows | ~3,840 | 10 |
| Cost / 10,000 rows | $1,600† | $1 |
† Assumes $25/hr analyst @400 rows/day
QualBot matches or exceeds human coders not because it's smarter, but because it never forgets your codebook, never gets tired, and applies rules with machine consistency—even after 10,000 responses.
Try It Yourself
Running a full coding job with QualBot is extremely simple:
- 📁 Upload your file
Select your open-ended data in either excel or csv format and upload it with one click. QualBot will validate the file automatically detect the columns containing your open-ended responses.
- 📔 Enter your codebook
Enter the codes you want to use to code your open-ended responses, or just paste a pre-existing codebook. QualBot will parse each line into a separate category and use it to code your open-ends.
- 🧾 Provide Metadata (Optional)
Metadata is optional, but it will give QualBot the necessary context to improve the accuracy of the coding exercise. Enter the research goal you had in mind for the open-ended item, the actual wording of the question, and any other contextual information that might help QualBot code your open-ends more accurately.

- 💰 Estimate cost and 🚀 go.
First, QualBot gives you a cost estimate—so there are no surprises. Once you approve it, the job runs automatically. When it's done, you'll get a clean CSV in your inbox with the assigned codes for each open-ended response.
Where We're Headed Next
We're just getting started. Here's what's brewing in the QualBot lab:
- Multi‑label coding: Because sometimes one category isn't enough.
- Auto codebook generation: No categories? No problem. We'll suggest them.
- Confidence filters: Choose whether to return scores, and sort by certainty.
- Sentiment tags: Automatically flag positive, negative, or neutral vibes.
- Live "Copilot" mode: Interactively probe, refine, and re-code in real time.
- Visual dashboards: Explore patterns in Sankey, sunburst, or histograms.
- Voting‑based accuracy: More models = more confidence = fewer regrets.
- Historical tuning: Tailor the model to how you think—based on your own past projects.
- Public benchmark challenge: Got weird data? Send it. We'll try to beat your humans.
You bring the words. We'll bring the structure. Ready to see it in action?
💡 Got an unusual dataset? Email us—we're assembling a public benchmark and would love to include your toughest cases.
References
Mellon, J., Bailey, J., Scott, R., Breckwoldt, J., Miori, M., & Schmedeman, P. (2024). Do AIs know what the most important issue is? Using language models to code open-text social survey responses at scale. Research & Politics, 11(1), 20531680241231468.