No Codebook? No Problem!
Introducing Codebook Induction
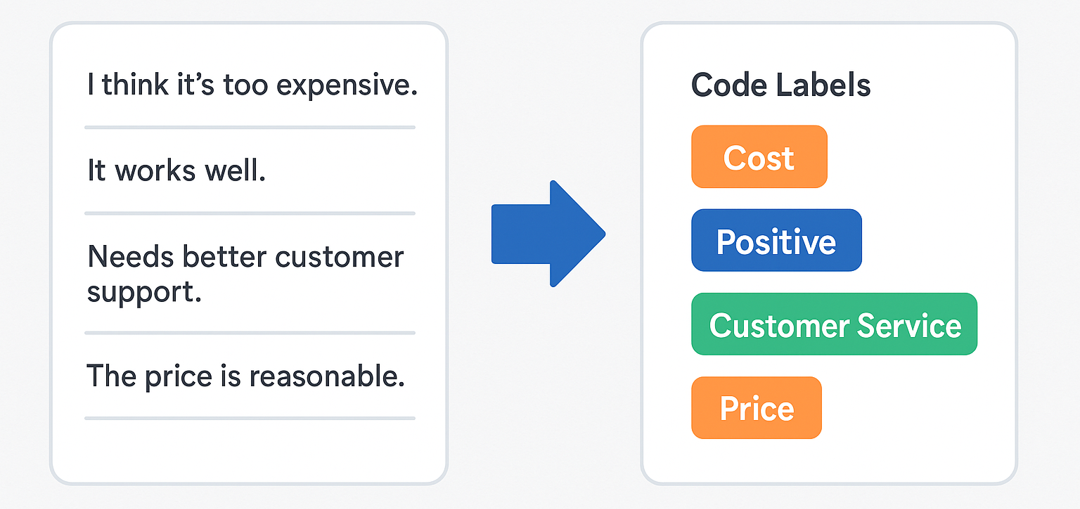
Sometimes, when working with open-ended data, we don't have a predefined codebook to guide the analysis. Creating one from scratch can be time-consuming, subjective, and labor intensive—especially when dealing with large volumes of responses. The new QualBot Coding "Suggest" button, helps you generate a concise and meaningful codebook in seconds, grounded in your actual data.
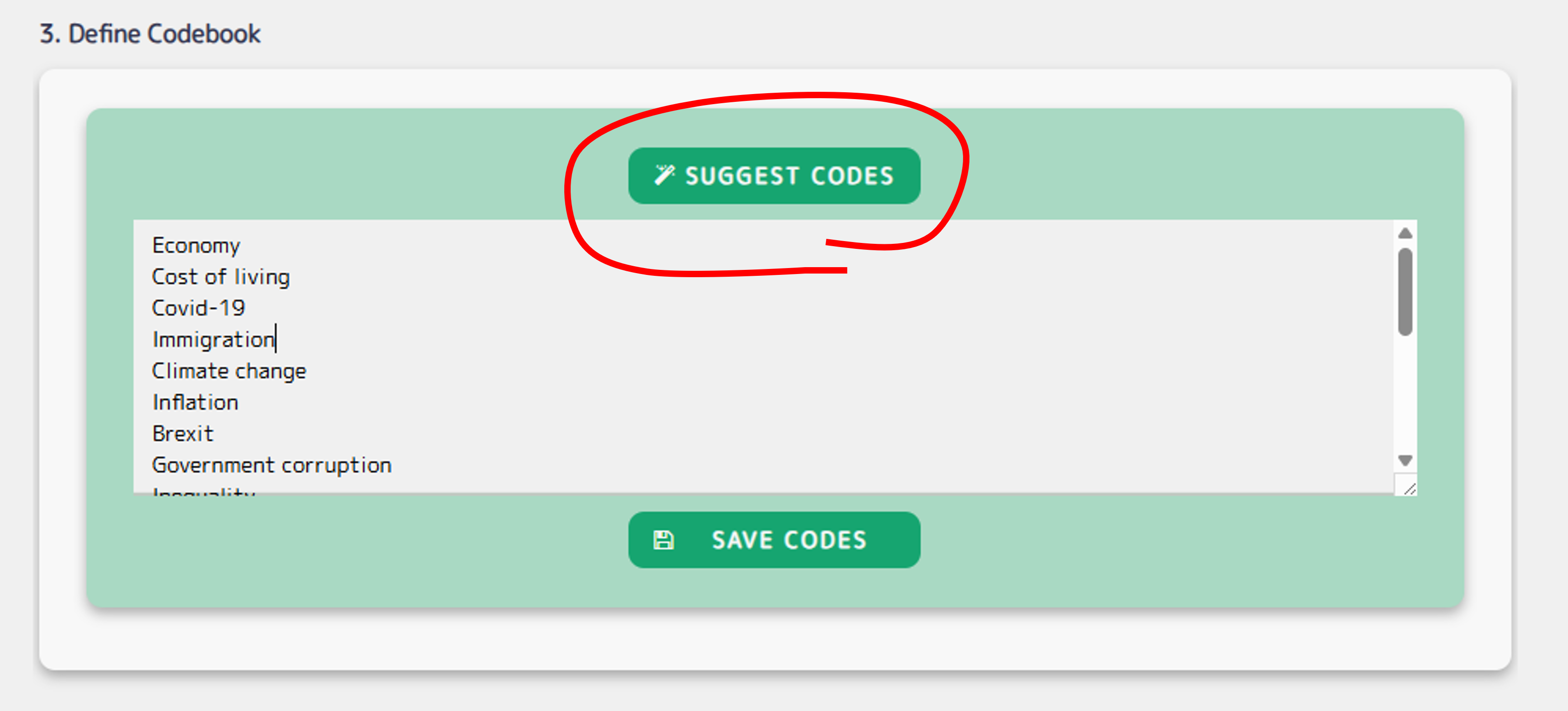
What Does the Codebook Induction Functionality Do?
The new suggest button automatically generates a shortlist of code labels from a column of open-ended responses in a CSV or Excel file. It samples the text adaptively and returns a concise, distinct set of suggested codes—each typically 1–3 words long. You can edit the suggested list directly, or regenerate by pushing the suggest codes button again.
Benchmarking QualBot's Codebook Induction
To validate our new code suggestion feature in QualBot, we benchmarked it against the gold-standard labels from the British Election Study (BES) using a sample of 1,000 open-ended responses.
In order to compare QualBot-generated codebooks to gold standard codebooks, we extracted two sets of codes using the new QualBot feature, one with 13 codes, another with 50 codes, matching the number of codes in the gold standard codebooks for the British Election Study "what's the most important issue today" item. We then used the QualBot coding feature to code 40,358 open-ended responses using the QualBot generated codebook, and compared the correspondence with the gold standard coded responses from waves 21 & 23 of the BES open dataset using the following metrics:
- Adjusted Rand Index (ARI) – for all pairs of responses, the ARI checks whether they were put in the same or different categories, adjusting for chance matches.
- Normalized Mutual Information (NMI) – measures whether QualBot labels and gold standard labels convey similar information, even if the category names differ.
- Coverage – percent of responses not labeled as "Other", indicating whether the generated list of codes sufficiently covers the corpus.
- Labels Used – how many distinct categories were actually used, indicating whether the generated list of codes produces irrelevant codes.
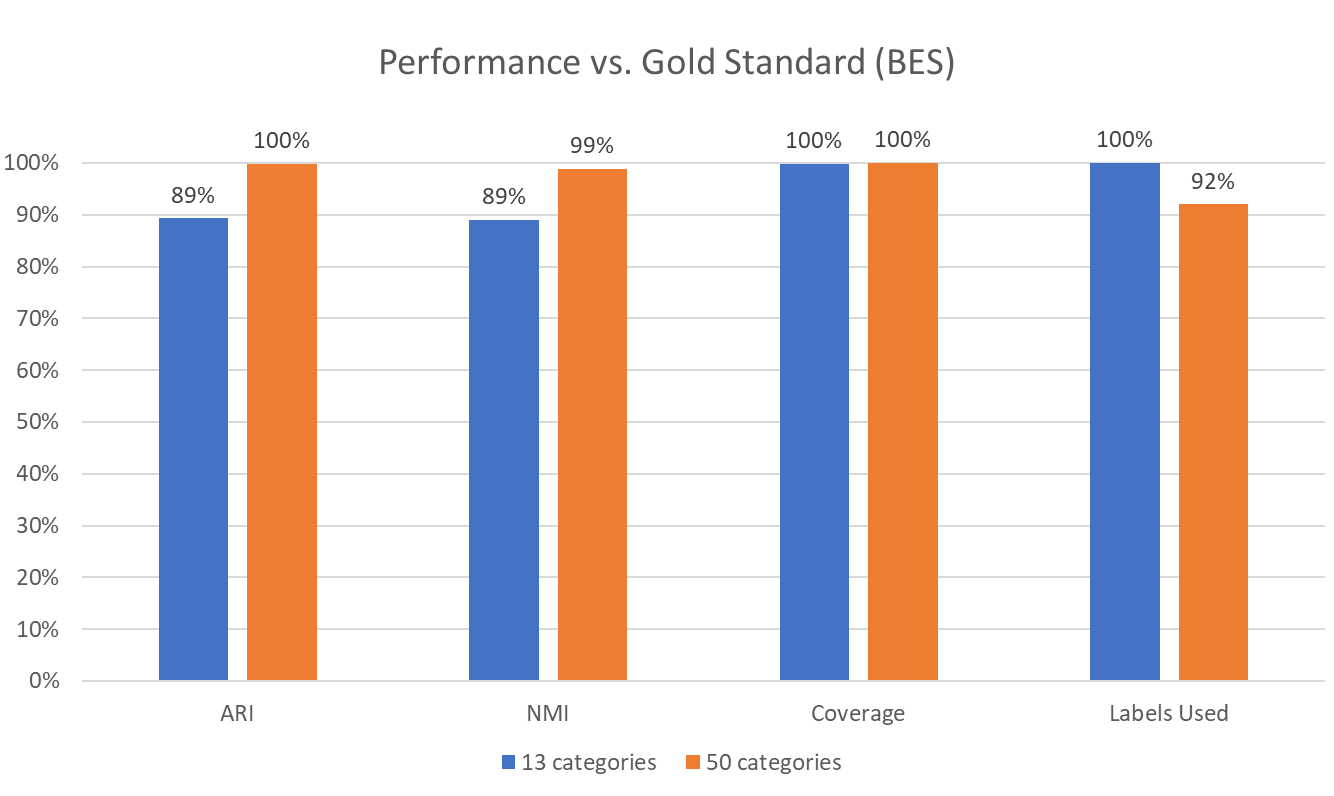
High ARI and NMI scores at both granularities show that QualBot's cluster assignments closely mirror the human-coded labels — both in structure (ARI) and shared meaning (NMI). 100% Coverage indicates that QualBot avoided fallback categories like "Other," which is critical in practical coding tasks where interpretability matters. Label utilization is excellent in the 13-category scheme and still strong in the 50-category version, suggesting a good balance between specificity and parsimony.
Bottom Line
These results show that QualBot's suggested codes achieve near-human agreement across different coding granularities. The 50-category version even edges out the 13-category one in clustering performance, demonstrating that the model scales well with complexity — an important feature for fine-grained qualitative analysis.